Workflows¶
Workflows consist of a DAG of Tasks. Tasks are bundled into Stages, but Stages have almost no functionality and are mostly just for keeping track of similar Tasks. Tasks execute as soon as their dependencies have completed.
To create your DAG, use Workflow.add_task(). Python generators
and comprehensions are a great way to do this in a very readable way.
from cosmos.api import Cosmos, py_call
def word_count(in_txt, out_txt, use_lines=False):
l = ' -l' if use_lines else ''
return subprocess.check_call(f"wc{l} {in_txt} > {out_txt}", check=True, shell=True)
cosmos = Cosmos('sqlite:///:memory:')
cosmos.initdb()
workflow = cosmos.start('My_Workflow', skip_confirm=True)
wc_tasks = [ workflow.add_task(func=word_count,
params=dict(in_txt=inp, out_txt=out),
uid=str(i))
for i, (inp, out) in enumerate((('a.txt', 'a_out.txt'), ('b.txt', 'b_out.txt'))) ]
# note this will create a_out.txt and b_out.txt in your current directory
workflow.run(cmd_wrapper=py_call)
Each call to Workflow.add_task() does the following:
Gets the corresponding Stage based on stage_name (which defaults to the name of of the task function, in this case “word_count”)
Checks to see if a Task with the same uid already completed successfully in that stage
If 2) is True, then return the successful Task instance (it will also be skipped when the DAG is run)
if 2) is False, then create and return a new Task instance
This allows you to easily change the code that produced a failed Task and resume where you left off.
Creating Your Job Dependency Graph (DAG)¶
A useful model for thinking about how your stages and tasks are related is to think in terms of SQL relationship types.
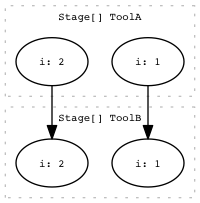
One2one (aka. map)¶
This is the most common type of dependency. For each task in StageA, you create a single dependent task in StageB.
cosmos = Cosmos()
cosmos.initdb()
workflow = cosmos.start('One2One')
for i in [1, 2]:
stageA_task = workflow.add_task(tool_a, params=dict(i=i), uid=i)
stageB_tasks = workflow.add_task(tool_b, params=stageA_task.params, parents=[stageA_task], uid=i)
draw_task_graph(workflow.task_graph(), 'one2one.png')
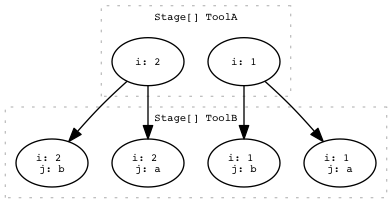
One2many (aka. scatter)¶
For each parent task in StageA, two or more new children are generated in StageB.
workflow = cosmos.start('One2Many')
for i in [1, 2]:
stageA_task = workflow.add_task(tool_a, params=dict(i=i)), uid=i)
for j in ['a','b']:
stageB_tasks = workflow.add_task(tool_b,
params=dict(j=j, **task.params),
parents=[stageA_task],
uid='%s_%s' % (i, j))
draw_task_graph(workflow.task_graph(), 'one2many.png')
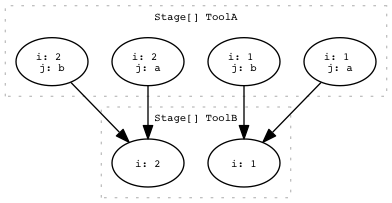
Many2one (aka. reduce or gather)¶
Two or more parents in StageA produce one task in StageB.
import itertools as it
workflow = cosmos.start('Many2One')
stageA_tasks = [workflow.add_task(tool_a, params=dict(i=i, j=j), uid='%s_%s'%(i,j))
for i in [1, 2]
for j in ['a','b'])]
get_i = lambda task: task.params['i']
stageB_task = workflow.add_task(tool_b, params=dict(i=i), parents=list(tasks), uid=i)
for i, tasks in it.groupby(sorted(stageA_tasks, key=get_i), get_i))
draw_task_graph(workflow.task_graph(), 'many2one.png')
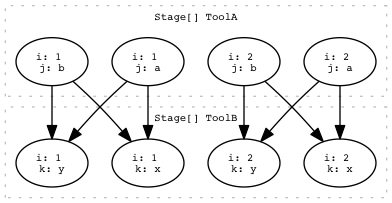
Many2many¶
Two or more parents in StageA produce two or more parents in StageB.
workflow = cosmos.start('many2many')
stageA_tasks = [workflow.add_task(tool_a, params=dict(i=i, j=j), uid='%s_%s' %(i,j))
for i in [1, 2]
for j in ['a','b'])]
def B_generator(stageA_tasks):
# For the more complicated relationships, it can be useful to define a generator
get_i = lambda task: task.params['i']
for i, tasks in it.groupby(sorted(stageA_tasks, key=get_i), get_i):
parents = list(tasks)
for k in ['x', 'y']:
yield workflow.add_task(tool_b, params=dict(i=i, k=k), parents=parents, uid='%s_%s' % (i,k))
stageB_tasks = listB_generator(stageA_tasks))
draw_task_graph(workflow.task_graph(), 'many2many.png')
API¶
Workflow¶
-
class
cosmos.api.Workflow(manual_instantiation=True, *args, **kwargs)[source]¶ An collection Stages and Tasks encoded as a DAG
-
add_task(func, params=None, parents=None, stage_name=None, uid=None, drm=None, queue=None, must_succeed=True, time_req=None, core_req=None, mem_req=None, gpu_req=None, max_attempts=None, noop=False, job_class=None, drm_options=None, environment_variables=None, if_duplicate='raise')[source]¶ Adds a new Task to the Workflow. If the Task already exists (and was successful), return the successful Task stored in the database
- Parameters
func (callable) – A function which returns a string which will get converted to a shell script to be executed. func will not get called until all of its dependencies have completed.
params (dict) – Parameters to func. Must be jsonable so that it can be stored in the database. Any Dependency objects will get resolved into a string, and the Dependency.task will be added to this Task’s parents.
parents (list[Tasks]) – A list of dependent Tasks.
uid (str) – A unique identifier for this Task, primarily used for skipping previously successful Tasks. If a Task with this stage_name and uid already exists in the database (and was successful), the database version will be returned and a new one will not be created.
stage_name (str) – The name of the Stage to add this Task to. Defaults to func.__name__.
drm (str) – The drm to use for this Task (example ‘local’, ‘ge’ or ‘drmaa:lsf’). Defaults to the default_drm parameter of
Cosmos.start()job_class – The name of a job_class to submit to; defaults to the default_job_class parameter of
Cosmos.start()queue – The name of a queue to submit to; defaults to the default_queue parameter of
Cosmos.start()must_succeed (bool) – Default True. If False, the Workflow will not fail if this Task does not succeed. Dependent Jobs will not be executed.
time_req (bool) – The time requirement; will set the Task.time_req attribute which is intended to be used by
get_submit_args()to request resources.core_req (int) – Number of cpus required for this Task. Can also be set in the params dict or the default value of the Task function signature, but this value takes precedence. Warning! In future versions, this will be the only way to set it.
mem_req (int) – Number of MB of RAM required for this Task. Can also be set in the params dict or the default value of the Task function signature, but this value takes predence. Warning! In future versions, this will be the only way to set it.
gpu_req (int) – Number of gpus required for this Task.
max_attempts (int) – The maximum number of times to retry a failed job. Defaults to the default_max_attempts parameter of
Cosmos.start()noop (bool) – Task is a No-op and will always be marked as successful.
drm_options (dict) – Options for Distributed Resource Management (cluster).
environment_variables (dict) – Environment variables to pass to the DRM (if supported).
if_duplicate (str) – If “raise”, raises an error if a Task with the same UID has already been added to this Workflow. If “return”, return that Task, allowing for an easy way to avoid duplicate work.
- Return type
cosmos.api.Task
-
run(max_cores=None, dry=False, set_successful=True, cmd_wrapper=<function default_cmd_fxn_wrapper>, log_out_dir_func=<function default_task_log_output_dir>, max_gpus=None, do_cleanup_atexit=True, lethal_signals=frozenset({<Signals.SIGINT: 2>, <Signals.SIGTERM: 15>, <Signals.SIGXCPU: 24>}))[source]¶ Runs this Workflow’s DAG
- Parameters
max_cores (int) – The maximum number of cores to use at once. A value of None indicates no maximum.
max_attempts (int) – The maximum number of times to retry a failed job. Can be overridden with on a per-Task basis with Workflow.add_task(…, max_attempts=N, …)
log_out_dir_func (callable) – A function that returns a Task’s logging directory (must be unique). It receives one parameter: the Task instance. By default a Task’s log output is stored in log/stage_name/task_id. See _default_task_log_output_dir for more info.
cmd_wrapper (callable) – A decorator which will be applied to every Task’s cmd_fxn.
dry (bool) – If True, do not actually run any jobs.
set_successful (bool) – Sets this workflow as successful if all tasks finish without a failure. You might set this to False if you intend to add and run more tasks in this workflow later.
do_cleanup_atexit – if False, do not attempt to cleanup unhandled exits.
lethal_signals – signals to catch and shutdown
Returns True if all tasks in the workflow ran successfully, False otherwise. If dry is specified, returns None.
-